先上效果图

===================================
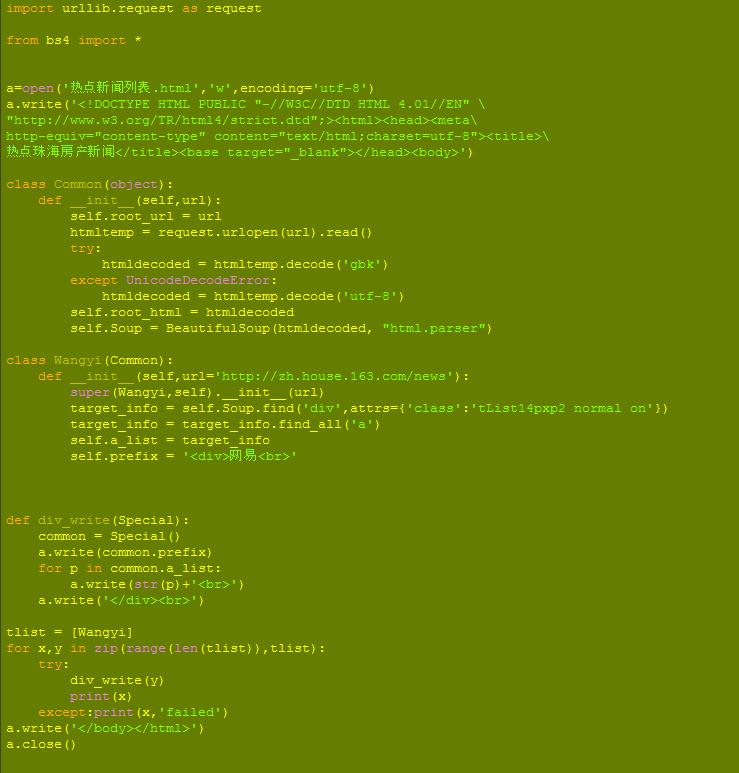
下面是代码
. as
from bs4 *
a=open(‘热点新闻列表.html’,’w’,=’utf-8′)
a.write(‘
“”;>’)
class ():
def (self,url):
self. = url
= .(url).read()
try:
= .(‘gbk’)
:
= .(‘utf-8’)
self. =
self.Soup = (, “html.”)
class ():
def (self,url=”):
super(,self).(url)
= self.Soup.find(‘div’,attrs={‘class’:’ on’})
= .(‘a’)
self. =
self. = ‘
‘
def ():
= ()
a.write(.)
for p in .:
a.write(str(p)+’
‘)
a.write(‘
‘)
tlist = []
for x,y in zip(range(len(tlist)),tlist):
try:
(y)
print(x)
:print(x,”)
a.write(”)
a.close()
这属于内容页分析部分,只要是相应地址的html上有的东西,都可以直接解析
———END———
限 时 特 惠: 本站每日持续更新海量各大内部创业教程,永久会员只需99元,全站资源免费下载 点击查看详情
站 长 微 信: hs105011
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。

